
 たぬ
たぬこんにちは、グロースハッカーの たぬ ( @tanuhack )です。
Python から BigQuery のテーブルを作成・更新(追加)するには、 pandas の関数を使うやり方と、 BigQuery API クライアントライブラリの google-cloud-bigquery モジュールを使うやり方の2種類の方法が存在します。
手軽なのは、前者のpandas.DataFrame のto_gcp メソッドを使う方ですが、Googleは後者の方を使って欲しそうなので、そちらを紹介します。参考:pandas-gbq との比較
google-cloud-bigquery には、テーブルを作成・追加する方法として、以下の4種類の関数が用意されています。
| メソッド | 説明 |
|---|---|
| load_table_from_dataframe | pandas の DataFrame からテーブルの内容をアップロード |
| load_table_from_file | ファイルからテーブルの内容をアップロード |
| load_table_from_json | JSON や dict からテーブルの内容をアップロード |
| load_table_from_uri | Cloud Storage からテーブルの内容をアップロード |
4つもあってどれを使えばいいか迷いそうですが、筆者はload_table_from_dataframeとload_table_from_json を場合に応じて使い分けています。例えば、基本は前者を使い、 ARRAY 型や STRUCT 型のようなテーブルを扱いたいときは後者を使うといった感じです。
この記事では、pandas の DataFrame からテーブルの内容をアップロードする load_table_from_dataframe の使い方を紹介します。
準備
モジュールのインストール
pip install google-auth
pip install google-cloud-bigquery
pip install pyarrow| モジュール | 説明 |
|---|---|
| google-auth | Google APIs との認証周り |
| google-cloud-bigquery | BigQuery API クライアントライブラリ |
| pyarrow | google-cloud-bigquery モジュールを使用するために必要。開発環境にインストールするだけで良い |
インポートと認証周り
import google.auth
from google.cloud import bigquery
scopes = ['https://www.googleapis.com/auth/bigquery']
creds, project_id = google.auth.default(scopes=scopes)
client = bigquery.Client(project=project_id, credentials=creds)サンプルのデータフレーム
この記事ではサンプルとして、以下のデータフレームを使用します。
import pandas as pd
df = pd.DataFrame(
{
'my_string': ['a', 'b', 'c'],
'my_bool': [True, True, False],
'my_int64': [1, 2, 3],
'my_float64': [4.0, 5.0, 6.0],
'my_date': [pd.Timestamp('1998-09-04'), pd.Timestamp('2010-09-13'), pd.Timestamp('2015-10-02')],
'my_datetime': [pd.Timestamp('1998-09-04T16:03:14', tz='Asia/Tokyo'), pd.Timestamp('2010-09-13T12:03:45', tz='Asia/Tokyo'), pd.Timestamp('2015-10-02T16:00:00', tz='Asia/Tokyo')],
}
)
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 3 entries, 0 to 2
# Data columns (total 6 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 my_string 3 non-null object
# 1 my_bool 3 non-null bool
# 2 my_int64 3 non-null int64
# 3 my_float64 3 non-null float64
# 4 my_date 3 non-null datetime64[ns]
# 5 my_datetime 3 non-null datetime64[ns, Asia/Tokyo]
# dtypes: bool(1), datetime64[ns, Asia/Tokyo](1), datetime64[ns](1), float64(1), int64(1), object(1)
# memory usage: 251.0+ bytes
# Noneテーブルを作成・更新する
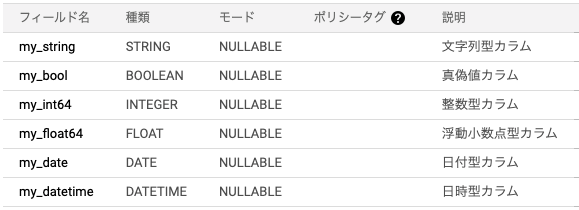
google-cloud-bigquery モジュールで BigQuery のテーブルを作成するには、bigquery.LoadJobConfigオブジェクトのschemaパラメータとwrite_dispositionパラメータを設定します。
schemaには、フィールド名やデータ型、モード、説明などを指定し、write_dispositionにはテーブル作成の書き方を指定します。
CREATE TABLE IF NOT EXISTS
同じ名前のテーブルが存在する場合は、作成しない方法です。
LoadJobConfigメソッドのwrite_dispositionパラメータに'WRITE_EMPTY'を指定します。
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('my_string', 'STRING', mode='NULLABLE', description='文字列型カラム'),
bigquery.SchemaField('my_bool', 'BOOL', mode='NULLABLE', description='真偽値カラム'),
bigquery.SchemaField('my_int64', 'INT64', mode='NULLABLE', description='整数型カラム'),
bigquery.SchemaField('my_float64', 'FLOAT64', mode='NULLABLE', description='浮動小数点型カラム'),
bigquery.SchemaField('my_date', 'DATE', mode='NULLABLE', description='日付型カラム'),
bigquery.SchemaField('my_datetime', 'DATETIME', mode='NULLABLE', description='日時型カラム'),
],
write_disposition='WRITE_EMPTY',
)
client.load_table_from_dataframe(df, '{dataset_id}.{table}', job_config=job_config).result()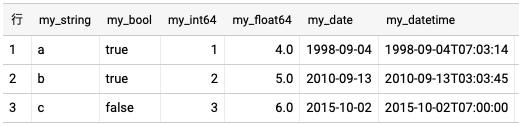
同じ名前のテーブルが存在する場合に実行した場合、エラーでプログラムが停止します。
CREATE OR REPLACE TABLE
同じ名前のテーブルが存在する場合は、上書きして作成する方法です。
LoadJobConfigメソッドのwrite_dispositionパラメータに'WRITE_TRUNCATE'を指定します。
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('my_string', 'STRING', mode='NULLABLE', description='文字列型カラム'),
bigquery.SchemaField('my_bool', 'BOOL', mode='NULLABLE', description='真偽値カラム'),
bigquery.SchemaField('my_int64', 'INT64', mode='NULLABLE', description='整数型カラム'),
bigquery.SchemaField('my_float64', 'FLOAT64', mode='NULLABLE', description='浮動小数点型カラム'),
bigquery.SchemaField('my_date', 'DATE', mode='NULLABLE', description='日付型カラム'),
bigquery.SchemaField('my_datetime', 'DATETIME', mode='NULLABLE', description='日時型カラム'),
],
write_disposition='WRITE_TRUNCATE',
)
client.load_table_from_dataframe(df, '{dataset_id}.{table}', job_config=job_config).result()INSERT
すでにテーブルが存在していて、そこにデータを追加したいときは、LoadJobConfigメソッドのwrite_dispositionパラメータに'WRITE_APPEND'を指定します。
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('my_string', 'STRING', mode='NULLABLE', description='文字列型カラム'),
bigquery.SchemaField('my_bool', 'BOOL', mode='NULLABLE', description='真偽値カラム'),
bigquery.SchemaField('my_int64', 'INT64', mode='NULLABLE', description='整数型カラム'),
bigquery.SchemaField('my_float64', 'FLOAT64', mode='NULLABLE', description='浮動小数点型カラム'),
bigquery.SchemaField('my_date', 'DATE', mode='NULLABLE', description='日付型カラム'),
bigquery.SchemaField('my_datetime', 'DATETIME', mode='NULLABLE', description='日時型カラム'),
],
write_disposition='WRITE_APPEND',
)
client.load_table_from_dataframe(df, '{dataset_id}.{table}', job_config=job_config).result()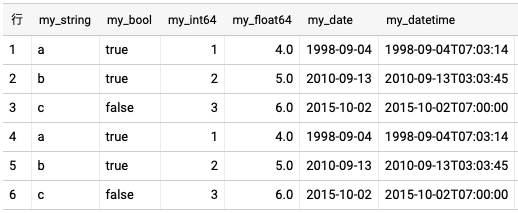
パーティション分割テーブルを作成する
BigQuery では、以下の条件でテーブルを分割できます。
- 時間単位の列
- 取り込み時間
- 整数範囲
時間単位の列
時間単位の列で分割テーブルを作成する場合は、LoadJobConfigメソッドのtime_partitioningパラメータにTimePartitioningオブジェクトを設定します。
type_:分割する単位(HOUR、DAY、MONTH、YEAR)、デフォルト:DAYfield:分割する列expiration_ms:パーティションの有効期限、デフォルト:60日
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('my_string', 'STRING', mode='NULLABLE', description='文字列型カラム'),
bigquery.SchemaField('my_bool', 'BOOL', mode='NULLABLE', description='真偽値カラム'),
bigquery.SchemaField('my_int64', 'INT64', mode='NULLABLE', description='整数型カラム'),
bigquery.SchemaField('my_float64', 'FLOAT64', mode='NULLABLE', description='浮動小数点型カラム'),
bigquery.SchemaField('my_date', 'DATE', mode='NULLABLE', description='日付型カラム'),
bigquery.SchemaField('my_datetime', 'DATETIME', mode='NULLABLE', description='日時型カラム'),
],
write_disposition='WRITE_EMPTY',
time_partitioning=bigquery.TimePartitioning(type_=bigquery.TimePartitioningType.DAY, field='my_datetime', expiration_ms=345600000000)
)
client.load_table_from_dataframe(df, '{dataset_id}.{table}', job_config=job_config).result()
参考
- google.cloud.bigquery.client.Client.load_table_from_dataframe | google-cloud-bigquery documentation
- google.cloud.bigquery.job.WriteDisposition | google-cloud-bigquery documentation
- パーティション分割テーブルの概要 | Google Cloud
- パーティション分割テーブルの作成 | Google Cloud
- google.cloud.bigquery.table.TimePartitioning | google-cloud-bigquery documentation


コメント