
 たぬ
たぬこんにちは、グロースハッカーの たぬ ( @tanuhack )です。
Notion API を使って、ワークスペースの全ユーザーリストを取得するには、下の URL を GET メソッドでリクエストします。
https://api.notion.com/v1/users公式リファレンス
https://developers.notion.com/reference/get-users
Pythonで Notion API を使用するには、公式の Notion SDK が用意されていないので、Requests モジュール などの HTTP 関数を使って直接 API を叩く必要があります。
ユーザーリストを取得する
基本
では、実際に Requests モジュールを使って、Notion API からユーザーリストを取得してみましょう。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
url = 'https://api.notion.com/v1/users'
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
}
r = requests.get(url, headers=headers)以下のようなレスポンスが返ってくれば成功しています。
from pprint import pprint
pprint(r.json(), sort_dicts=False)
# {'object': 'list',
# 'results': [{'object': 'user',
# 'id': '*****************',
# 'name': '*****************',
# 'avatar_url': '*****************.png',
# 'type': 'person',
# 'person': {'email': '*****************@boul.tech'}},
# ︙
# {'object': 'user',
# 'id': '*****************',
# 'name': '*****************',
# 'avatar_url': None,
# 'type': 'bot',
# 'bot': {}}],
# 'next_cursor': None,
# 'has_more': False}実際にデータフレームに渡すユーザーリストの部分はresultsプロパティに格納されているで、data変数に代入しておくと便利です。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
url = 'https://api.notion.com/v1/users'
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
}
r = requests.get(url, headers=headers)
+ data = r.json().get('results')print(data)
# [{'object': 'user',
# 'id': '*****************',
# 'name': '*****************',
# 'avatar_url': '*****************.png',
# 'type': 'person',
# 'person': {'email': '**********@boul.tech'}},
# ︙
# {'object': 'user',
# 'id': '*****************',
# 'name': '*****************',
# 'avatar_url': None,
# 'type': 'bot',
# 'bot': {}}]取得する人数を調整する
クエリパラメータのpage_sizeに値を設定してリクエストすると、取得するユーザーリストの人数を変更することができます。
page_sizeパラメータのデフォルト値は 100 で、最大値も 100 です。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
url = 'https://api.notion.com/v1/users'
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
}
- r = requests.get(url, headers=headers)
+ payload = {'page_size': 100}
+ r = requests.get(url, headers=headers, params=payload)
data = r.json().get('results')ただしこの方法だと、メンバーが 100 人越えた場合、溢れた分のユーザーデータを取得することができません。
100 人越えたタイミングで編集するのはプログラムとしてどうなの?という話なので、いつでも 100 人越えても OK な状態にしておくことが理想的です。
100人以上のデータを取得する
レスポンスのhas_moreプロパティには次のユーザーリストが存在するかという ブール値 が格納されおり、次のユーザーリストが存在していれば、next_cursorプロパティにエンドポイントが格納されます。
次のユーザーリストが存在する場合
{
'object': 'list',
'results': […],
'next_cursor': None,
'has_more': False
}次のユーザーリストが存在しない場合
{
'object': 'list',
'results': […],
'next_cursor': '*******************',
'has_more': True
}クエリパラメータのstart_cursorに適切なエンドポイントをセットすると、指定されたカーソルの後から始まる結果を得ることができます。
後は、レスポンスのhas_moreプロパティがFalseになるまでwhile文でループさせれば、100人以上のユーザーリストを取得できることが分かりますね。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
+ loop_cnt = 0
+ has_more = True
+ data = []
+ while has_more:
+ loop_cnt += 1
url = 'https://api.notion.com/v1/users'
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
}
- payload = {'page_size': 100}
+ payload = {'page_size': 100} if loop_cnt == 1 else {'page_size': 100, 'start_cursor': next_cursor}
r = requests.get(url, headers=headers, params=payload)
- data = r.json().get('results')
+ data += r.json().get('results')
+ has_more = r.json().get('has_more')
+ next_cursor = r.json().get('next_cursor')三項演算子を使って、ループが2回以上になるとstart_cursorパラメータにエンドポイントを設定するようにしました。
データフレームとして取得する
レスポンスのユーザーリスト部分(resultsプロパティ)の内容が 辞書のリスト になっているので、
print(data)
# [{'object': 'user',
# 'id': '*****************',
# 'name': '*****************',
# 'avatar_url': '*****************.png',
# 'type': 'person',
# 'person': {'email': '**********@boul.tech'}},
# ︙
# {'object': 'user',
# 'id': '*****************',
# 'name': '*****************',
# 'avatar_url': None,
# 'type': 'bot',
# 'bot': {}}]pandas のpd.DataFrame(辞書のリスト)で簡単にデータフレームを作成することができます。
df = pd.DataFrame(data)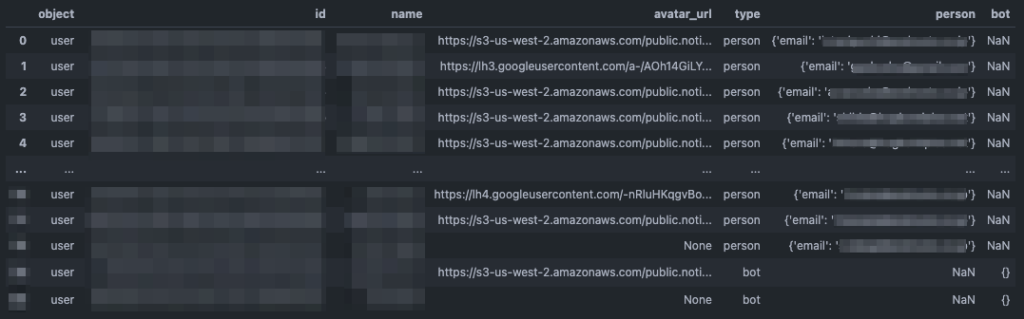
ユーザーオブジェクトの内容は User object ページで確認できるので、あとは、必要な分だけ前処理をして完成です。
df = pd.DataFrame(data)
+ # 欠損値を pd.NA に統一
+ df = df.mask(df.isnull(), pd.NA)
+ # person列からemailの値を取り出し、新しくemail列を作成
+ df['email'] = df['person'].mask(df['person'].isnull(), {}).apply(lambda n: n.get('email', pd.NA))
+ # 不要な列を削除
+ df = df.drop(columns=['person', 'bot'])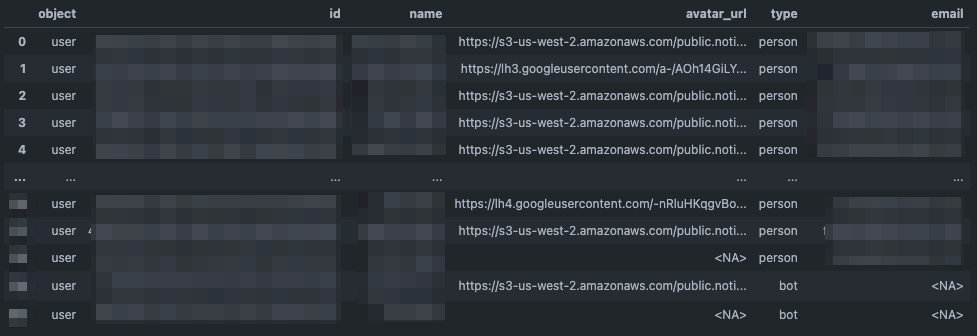


コメント