
 たぬ
たぬこんにちは、グロースハッカーの たぬ ( @tanuhack )です。
Notion API を使って、データベースを取得するには、下の URL を POST メソッドでリクエストします。
https://api.notion.com/v1/databases/{ データベースID }/query公式リファレンス
https://developers.notion.com/reference/post-database-query
Pythonで Notion API を使用するには、公式の Notion SDK が用意されていないので、Requests モジュール などの HTTP 関数を使って直接 API を叩く必要があります。
準備
トークンを取得する
別の記事で紹介する予定なので割愛します。
データベースを作成する
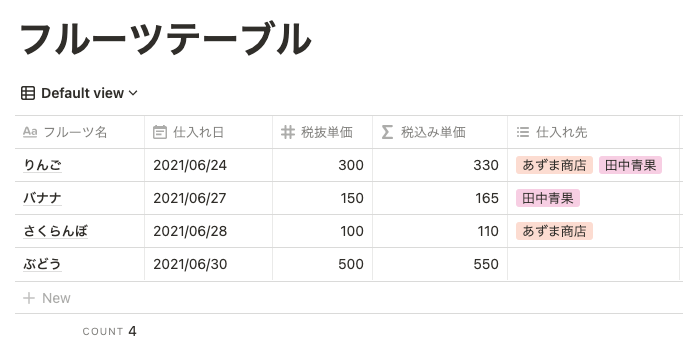
例として、下の画像のようなデータベースを用意しました。ぶどうの仕入れ先はあえて空白にしています。
Botとデータベースを紐付ける
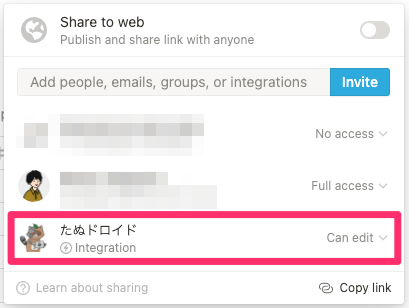
データベースページのshareボタンで Bot(Integration)をデータベースを紐付けます。Bot ユーザーの権限はCan editのみ設定できます。
データベースIDを取得する
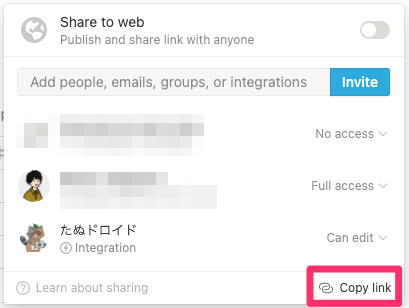
データベース ID は、データベースページの URL から取得できます。
https://www.notion.so/***********/{ データベースID(32文字) }?v=...デスクトップアプリで確認する場合は、ShareからCopy linkを選択します。
インラインデータベースを使用している場合は、データベースがフルページで表示されていることを確認してください。
データベースを取得する
基本
では、実際に Requests モジュールを使って、Notion API からデータベースを取得してみましょう。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
NOTION_DATABASE_ID = '{ データベースID }'
url = f"https://api.notion.com/v1/databases/{NOTION_DATABASE_ID}/query"
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
'Content-Type': 'application/json',
}
r = requests.post(url, headers=headers)以下のようなレスポンスが返ってくれば成功しています。
from pprint import pprint
pprint(r.json(), sort_dicts=False)
# {'object': 'list',
# 'results': [{'object': 'page',
# 'id': '*****************',
# 'created_time': '2021-06-30T09:33:00.000Z',
# 'last_edited_time': '2021-06-30T09:33:00.000Z',
# 'parent': {'type': 'database_id',
# 'database_id': '*****************'},
# 'archived': False,
# 'properties': {…}
# 'url': 'https://www.notion.so/*****************'},
# ︙
# {'object': 'page',
# 'id': '*****************',
# 'created_time': '2021-06-30T09:33:00.000Z',
# 'last_edited_time': '2021-06-30T09:33:00.000Z',
# 'parent': {'type': 'database_id',
# 'database_id': '*****************'},
# 'archived': False,
# 'properties': {…}
# 'url': 'https://www.notion.so/*****************'}],
# 'next_cursor': None,
# 'has_more': False}| プロパティ | 説明 |
|---|---|
'object' | 'list'のみ |
'results.object' | 'page'のみ |
'results.id' | ページID |
'results.created_time' | ページが作成された日時 |
'results.last_edited_time' | ページが編集された日時 |
'results.parent' | ページの親要素のデータベース情報 |
'results.archived' | アーカイブフラグ |
'results.properties' | ページのプロパティ情報(コンテンツ) |
'results.url' | ページのURL |
'next_cursor' | エンドポイント |
'has_more' | 次のページがあるかどうかのフラグ |
実際にデータフレームに渡すデータベースの部分はresultsプロパティに格納されているでdata変数に代入すると便利です。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
NOTION_DATABASE_ID = '{ データベースID }'
url = f"https://api.notion.com/v1/databases/{NOTION_DATABASE_ID}/query"
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
'Content-Type': 'application/json',
}
r = requests.post(url, headers=headers)
+ data = r.json().get('results')print(data)
# [{'object': 'page',
# 'id': '*****************',
# 'created_time': '2021-06-30T09:33:00.000Z',
# 'last_edited_time': '2021-06-30T09:33:00.000Z',
# 'parent': {'type': 'database_id',
# 'database_id': '*****************'},
# 'archived': False,
# 'properties': {…}
# 'url': 'https://www.notion.so/*****************'},
# ︙
# {'object': 'page',
# 'id': '*****************',
# 'created_time': '2021-06-30T09:33:00.000Z',
# 'last_edited_time': '2021-06-30T09:33:00.000Z',
# 'parent': {'type': 'database_id',
# 'database_id': '*****************'},
# 'archived': False,
# 'properties': {…}
# 'url': 'https://www.notion.so/*****************'}]そして更に、コンテンツの部分はpropertiesプロパティに格納されているので、contents変数に代入しておくと便利です。
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
NOTION_DATABASE_ID = '{ データベースID }'
url = f"https://api.notion.com/v1/databases/{NOTION_DATABASE_ID}/query"
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
'Content-Type': 'application/json',
}
r = requests.post(url, headers=headers)
data = r.json().get('results')
+ contents = [i['properties'] for i in data]from pprint import pprint
pprint(contents, sort_dicts=False)
# [{'仕入れ先': {'id': 'UTPo', 'type': 'multi_select', 'multi_select': []},
# '税込み単価': {'id': 'fGIy',
# 'type': 'formula',
# 'formula': {'type': 'number', 'number': 550}},
# '仕入れ日': {'id': 'q{;]',
# 'type': 'date',
# 'date': {'start': '2021-06-30', 'end': None}},
# '税抜単価': {'id': '~HD^', 'type': 'number', 'number': 500},
# 'フルーツ名': {'id': 'title',
# 'type': 'title',
# 'title': [{'type': 'text',
# 'text': {'content': 'ぶどう', 'link': None},
# 'annotations': {'bold': False,
# 'italic': False,
# 'strikethrough': False,
# 'underline': False,
# 'code': False,
# 'color': 'default'},
# 'plain_text': 'ぶどう',
# 'href': None}]}},
# ︙
# {'仕入れ先': {'id': 'UTPo',
# 'type': 'multi_select',
# 'multi_select': [{'id': '*********************',
# 'name': 'あずま商店',
# 'color': 'orange'},
# {'id': '*********************',
# 'name': '田中青果',
# 'color': 'pink'}]},
# '税込み単価': {'id': 'fGIy',
# 'type': 'formula',
# 'formula': {'type': 'number', 'number': 330}},
# '仕入れ日': {'id': 'q{;]',
# 'type': 'date',
# 'date': {'start': '2021-06-24', 'end': None}},
# '税抜単価': {'id': '~HD^', 'type': 'number', 'number': 300},
# 'フルーツ名': {'id': 'title',
# 'type': 'title',
# 'title': [{'type': 'text',
# 'text': {'content': 'りんご', 'link': None},
# 'annotations': {'bold': False,
# 'italic': False,
# 'strikethrough': False,
# 'underline': False,
# 'code': False,
# 'color': 'default'},
# 'plain_text': 'りんご',
# 'href': None}]}}]取得するページ数を調整する
リクエストボディのpage_sizeパラメータに値を設定すると、取得するデータベースのページ数(行数)を変更することができます。
page_sizeパラメータのデフォルト値は 100 で、最大値も 100 です。
+ import json
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
NOTION_DATABASE_ID = '{ データベースID }'
url = f"https://api.notion.com/v1/databases/{NOTION_DATABASE_ID}/query"
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
'Content-Type': 'application/json',
}
- r = requests.post(url, headers=headers)
+ payload = {'page_size': 100}
+ r = requests.post(url, headers=headers, data=json.dumps(payload))
data = r.json().get('results')
contents = [i['properties'] for i in data]ただしこの方法だと、データベースのページ数が 100 人越えた場合、溢れた分のデータを取得することができません。
100 ページ越えたタイミングで編集するのはプログラムとしてどうなの?という話なので、いつでも 100 ページ越えても OK な状態にしておくことが理想的です。
100ページ以上のデータを取得する
レスポンスのhas_moreプロパティには次のページが存在するかという ブール値 が格納されおり、次のページが存在していれば、next_cursorプロパティにエンドポイントが格納されます。
次のユーザーリストが存在する場合
{
'object': 'list',
'results': […],
'next_cursor': None,
'has_more': False
}次のユーザーリストが存在しない場合
{
'object': 'list',
'results': […],
'next_cursor': '*******************',
'has_more': True
}リクエストボディのstart_cursorに適切なエンドポイントをセットすると、指定されたカーソルの後から始まる結果を得ることができます。
後は、レスポンスのhas_moreプロパティがFalseになるまでwhile文でループさせれば、100ページ以上のデータベースを取得できることが分かりますね。
import json
import requests
NOTION_ACCESS_TOKEN = '{ トークン }'
NOTION_DATABASE_ID = '{ データベースID }'
+ loop_cnt = 0
+ has_more = True
+ data = []
+ while has_more:
+ loop_cnt += 1
url = f"https://api.notion.com/v1/databases/{NOTION_DATABASE_ID}/query"
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
'Content-Type': 'application/json',
}
- payload = {'page_size': 100}
+ payload = {'page_size': 100} if loop_cnt == 1 else {'page_size': 100, 'start_cursor': next_cursor}
r = requests.post(url, headers=headers, data=json.dumps(payload))
data = r.json().get('results')
+ data += r.json().get('results')
+ has_more = r.json().get('has_more')
+ next_cursor = r.json().get('next_cursor')
contents = [i['properties'] for i in data]三項演算子を使って、ループが2回以上になるとstart_cursorパラメータにエンドポイントを設定するようにしました。
データフレームとして取得する
基本
レスポンスのプロパティ部分(propertiesプロパティ)の内容が 辞書のリスト になっているので、
from pprint import pprint
pprint(contents, sort_dicts=False)
# [{'仕入れ先': {'id': 'UTPo', 'type': 'multi_select', 'multi_select': []},
# '税込み単価': {'id': 'fGIy',
# 'type': 'formula',
# 'formula': {'type': 'number', 'number': 550}},
# '仕入れ日': {'id': 'q{;]',
# 'type': 'date',
# 'date': {'start': '2021-06-30', 'end': None}},
# '税抜単価': {'id': '~HD^', 'type': 'number', 'number': 500},
# 'フルーツ名': {'id': 'title',
# 'type': 'title',
# 'title': [{'type': 'text',
# 'text': {'content': 'ぶどう', 'link': None},
# 'annotations': {'bold': False,
# 'italic': False,
# 'strikethrough': False,
# 'underline': False,
# 'code': False,
# 'color': 'default'},
# 'plain_text': 'ぶどう',
# 'href': None}]}},
# ︙
# {'仕入れ先': {'id': 'UTPo',
# 'type': 'multi_select',
# 'multi_select': [{'id': '*********************',
# 'name': 'あずま商店',
# 'color': 'orange'},
# {'id': '*********************',
# 'name': '田中青果',
# 'color': 'pink'}]},
# '税込み単価': {'id': 'fGIy',
# 'type': 'formula',
# 'formula': {'type': 'number', 'number': 330}},
# '仕入れ日': {'id': 'q{;]',
# 'type': 'date',
# 'date': {'start': '2021-06-24', 'end': None}},
# '税抜単価': {'id': '~HD^', 'type': 'number', 'number': 300},
# 'フルーツ名': {'id': 'title',
# 'type': 'title',
# 'title': [{'type': 'text',
# 'text': {'content': 'りんご', 'link': None},
# 'annotations': {'bold': False,
# 'italic': False,
# 'strikethrough': False,
# 'underline': False,
# 'code': False,
# 'color': 'default'},
# 'plain_text': 'りんご',
# 'href': None}]}}]pandas のpd.DataFrame(辞書のリスト)で簡単にデータフレームを作成することができます。
df = pd.DataFrame(contents)
ただし、データフレームの全てのフィールドの要素が 辞書 になっているので、pandas.DataFrameのapplymap関数を使って、1つのフィールドごとに関数を適用させて値の部分だけを取得したいと思います。
以下のプログラムで、全てのプロパティタイプにおいて、値の部分だけを取得する関数を自作しました。
リレーションプロパティの複数キーの場合をテストしていないので、そのあたりは自己責任で利用してください。
import pandas as pd
def get_property_value(d):
"""
プロパティの値を取得する関数
"""
property_type = d.get('type')
if property_type in ['title']:
return d[property_type][0]['plain_text'] if d[property_type] else pd.NA
elif property_type in ['number', 'checkbox', 'url', 'email', 'phone_number', 'created_time', 'last_edited_time']:
return d[property_type]
elif property_type in ['select']:
return d[property_type]['name']
elif property_type == 'multi_select':
return [i.get('name') for i in d[property_type]]
elif property_type == 'date':
return {'start': d[property_type]['start'], 'end': d[property_type]['end']}
elif property_type == 'people':
return [i['id'] for i in d[property_type]]
elif property_type == 'files':
return [i['name'] for i in d[property_type]]
elif property_type in ['created_by', 'last_edited_by']:
return d[property_type]['id']
elif property_type == 'formula':
return get_property_value(d[property_type])
elif property_type == 'relation':
return d[property_type][0]['id'] if d[property_type] else pd.NA
elif property_type == 'rollup':
return get_property_value(d[property_type]['array'][0])
else:
return pd.NA
df = pd.DataFrame(contents)
# 欠損値を空の辞書に置換
df = df.mask(df.isnull(), {})
# 全てのフィールドに対して、関数を実行
df = df.applymap(get_property_value)
# 列を並び替え
df = df[['フルーツ名', '仕入れ日', '税抜単価', '税込み単価', '仕入れ先']]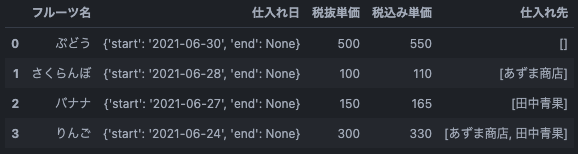
各レコードにページIDを付与する
data変数には、コンテンツの他にもデータベースのメタ情報が格納されていましたね。
print(data)
# [{'object': 'page',
# 'id': '*****************',
# 'created_time': '2021-06-30T09:33:00.000Z',
# 'last_edited_time': '2021-06-30T09:33:00.000Z',
# 'parent': {'type': 'database_id',
# 'database_id': '*****************'},
# 'archived': False,
# 'properties': {…}
# 'url': 'https://www.notion.so/*****************'},
# ︙
# {'object': 'page',
# 'id': '*****************',
# 'created_time': '2021-06-30T09:33:00.000Z',
# 'last_edited_time': '2021-06-30T09:33:00.000Z',
# 'parent': {'type': 'database_id',
# 'database_id': '*****************'},
# 'archived': False,
# 'properties': {…}
# 'url': 'https://www.notion.so/*****************'}]メタ情報の中から、ページIDを抜き出し、データフレームに結合しておくと後々良いことがあるかもしれません。
df = pd.DataFrame(contents)
# 欠損値を空の辞書に置換
df = df.mask(df.isnull(), {})
# 全てのフィールドに対して、関数を実行
df = df.applymap(get_property_value)
# 列を並び替え
df = df[['フルーツ名', '仕入れ日', '税抜単価', '税込み単価', '仕入れ先']]
+ # ページIDを追加
+ df = pd.concat([pd.DataFrame(data)['id'], df], axis=1)


コメント